Programa Rising Leaders Brasil
Aulas de inglês com foco em desenvolvimento em carreira

Adriele Rocha

Hi, I’m Adriele Rocha Weisz, a Data Engineer & Data Architect based in Switzerland.
I specialize in scalable pipelines, data infrastructure, and data compliance for both medical and non-medical sectors





I bring strong analytical thinking and adaptability, allowing me to solve complex problems and quickly master new technologies. My communication skills help me bridge technical and non-technical teams, ensuring clarity across all project phases. I thrive in diverse, cross-functional environments and have led initiatives from concept to deployment with a collaborative mindset.
You can take a look in my Linkedin and Github, or you can email for further questions

Hi! I’m passionate about building clean, scalable, and purpose-driven data systems. I have a background that blends data engineering, software development, and regulatory compliance, I thrive at the intersection of technology and real-world impact. My main motivation is to see a positive and sustainable impact for all stakeholders.
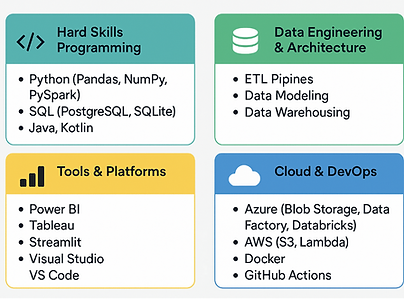
Over the past few years, I’ve worked in multiple industries aound the world—from healthcare and sensor technology to agriculture and aerospace—building everything from real-time data pipelines using Python and Docker, to data infrastructure on Azure and AWS, and even developing mobile applications in Kotlin and Java.
About me




Scalable Azure-First Streaming Data Lakehouse Pipeline with ML, Kubernetes, and Terraform
This project is an end-to-end data engineering pipeline designed to simulate, ingest, process, and analyze real-time operational data from railway traction systems. The project integrates Machine Learning, Azure-native cloud architecture, Kubernetes automation, and Agile delivery—showcasing top-level data engineering practices in a high-availability industrial context
Tools & Technologies Used:
-
Python, PySpark, pandas – data simulation, processing, and feature engineering
-
Azure Blob Storage, Databricks, Delta Lake – scalable ingestion and transformation
-
Scikit-learn, MLflow – failure prediction model with versioned tracking
-
Power BI – interactive dashboards for maintenance, energy, and fault analytics
-
Kubernetes – CronJobs for automated data stream simulation
-
Terraform – infrastructure-as-code for deploying Azure resources
-
Agile & DevOps – modular, sprint-based delivery with full CI/CD structure
Workflow Overview:
-
Simulated five operational data domains (telemetry, vehicle usage, maintenance, energy costs, weather)
-
Ingested raw JSON data into Azure Blob Storage Bronze Layer
-
Structured data in Silver Layer and aggregated features in Gold Layer using Databricks
-
Trained a Random Forest model to classify potential failures, logged results with MLflow
-
Deployed simulators via Kubernetes CronJobs and designed infrastructure using Terraform modules
Result: A cloud-native, modular, and production-grade predictive maintenance system for the rail industry — ideal for showcasing data engineering maturity, real-time analytics, and ML lifecycle management in Azure environments.
Machine Learning-Based Customer Retention Engine
This project uses Machine Learning to predict which customers are most likely to leave, empowering businesses to take early action and reduce churn. The pipeline includes data cleaning, model training, and insight generation based on real behavioral data.
Tools & Technologies Used:
-
Python, Pandas, NumPy – data preparation and analysis
-
Scikit-learn – ML models (Logistic Regression, Random Forest, XGBoost)
-
SQLite + SQL – for structured queries and storage
-
Matplotlib & Seaborn – data visualization
-
Streamlit (optional) – dashboard creation for business users
Workflow Overview:
-
Cleaned the raw customer dataset (handled nulls, encoded variables)
-
Engineered features such as contract type, tenure, and charges
-
Trained multiple ML models and evaluated performance using metrics like F1-score
-
Extracted churn risk and key predictors
-
Delivered insights through dashboard-ready outputs
Result: A powerful predictive tool that estimates customer churn risk and highlights the features driving those decisions — perfect for marketing, customer success, or strategic teams.
CloudETL360: Scalable Data Lakehouse on Azure
This project demonstrates an end-to-end data pipeline that simulates a real manufacturing environment — transforming raw data into meaningful business insights using Azure’s cloud ecosystem.
Tools & Technologies Used:
-
Python – data simulation and SQLite generation
-
SQLite – structured local data source
-
Azure Blob Storage – scalable cloud file storage
-
Azure Databricks + PySpark – ETL & data lakehouse processing
-
Power BI – visualization of final metrics
Workflow Overview:
-
Simulate raw manufacturing data (product ID, defect rate, temperature, etc.) in SQLite
-
Upload .db file to Azure Blob Storage using Azure SDK
-
Mount Blob Storage to Azure Databricks File System (DBFS)
-
Use PySpark to classify data into:
-
Bronze: Raw unprocessed files
-
Silver: Cleaned structured data
-
Gold: Aggregated KPIs (e.g. defect rate by location)
-
-
Export .parquet files and load into Power BI for reporting
Result: A cloud-native data pipeline capable of scaling from PoC to production. It follows a Lakehouse pattern, is fully automatable, and delivers clean data to the business via interactive dashboards.
End-to-End CI/CD Pipeline with Docker & GitHub Actions
This project demonstrates how I automated the build, test, and deployment process for a Python application using containerization and DevOps practices.
Tools & Technologies Used:
-
Python (Flask)
-
GitHub Actions for CI/CD
-
Docker for containerization
-
Python’s unittest for test automation
Workflow Overview:
-
I push code to GitHub.
-
GitHub Actions automatically installs dependencies, runs unit tests, builds a Docker image, and pushes it to Docker Hub.
-
The app runs on a local Docker container — fully tested and reproducible.
Result: The application is continuously tested and packaged in a Docker container every time code is pushed — no manual steps. This ensures fast delivery, better quality, and reproducibility for modern data solutions.
Email, Linkedin and Github Link



